

Le aziende generano e accumulano dati da decenni su sistemi quali ERP, CRM, fogli Excel, Data Warehouse, log applicativi, e-mail, documenti e file dai formati più disparati. È un patrimonio enorme, distribuito, più o meno accessibile, a volte ridondante. Eppure, se chiedessimo a un analista, a un manager o a un nuovo dipendente qual è il significato di margine operativo per l’azienda e come si calcola, otterremmo risposte dubbiose, forse discordanti. Perché, e come risolvere?
Key Points
- Senza un’architettura della conoscenza condivisa, gli agenti AI non possono interpretare correttamente il significato dei dati aziendali: serve un layer semantico esplicito e governato, capace di trasformare informazioni frammentate in conoscenza affidabile.
- La Knowledge Architecture si costruisce attraverso un percorso evolutivo composto da diversi livelli progressivi: si parte dal Conceptual Data Model fino ad arrivare a Knowledge Graph e Semantic Layer. Ogni fase produce asset informativi strutturati che alimentano quella successiva.
- La governance della Knowledge Architecture è una necessità architetturale, perché gli agenti AI basano decisioni e azioni su ciò che comprendono dal layer semantico: definizioni obsolete, relazioni errate o controlli insufficienti rischiano di propagare errori lungo workflow e processi interconnessi.
Un problema diffuso: la mancanza di linguaggio comune e comprensione univoca dei dati aziendali
Il problema appena descritto è noto, ma con l'avvento degli agenti AI, sistemi autonomi che leggono, interrogano, ragionano sui dati aziendali e a volte decidono e agiscono, il problema diventa critico. Il motivo è che un agente AI non riesce facilmente a “intuire dal contesto" cosa intende l'azienda per cliente attivo, prodotto finito o ricavo netto. Ha bisogno di un contratto semantico esplicito, formale e navigabile. Ha bisogno di un'architettura della conoscenza.
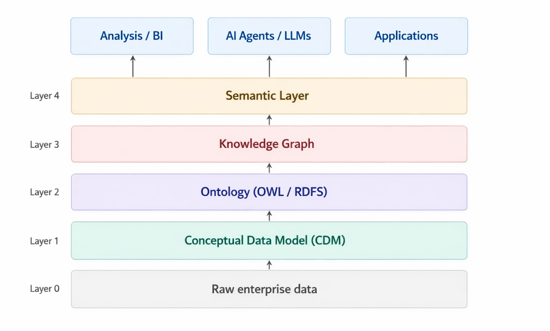
Knowledge Architecture: quattro concetti, una sola catena
Prima di approfondire la costruzione di questa Knowledge Architecture occorre comprendere bene quattro espressioni diverse che spesso vengono usate impropriamente o in sovrapposizione: Conceptual Data Model, Ontologia, Knowledge Graph e Semantic Layer. Non sono sinonimi, ma strati diversi di un'unica architettura, ognuno con un ruolo ben preciso.
Conceptual Data Model, la rappresentazione del mondo aziendale (Layer 1)
Il Conceptual Data Model (CDM) è il punto di partenza della Knowledge Architecture. È una rappresentazione concettuale del contesto di business, agnostica rispetto a qualsiasi tecnologia di creazione, acquisizione o gestione dei dati. Serve a rappresentare le entità più rilevanti per il business (esempio: cliente, prodotto, fornitore, ordine di vendita, fattura, registrazione contabile, dipendente, ecc.) e come si relazionano tra loro (esempio: un cliente effettua ordini, un ordine contiene prodotti). In alcuni contesti, se il CDM non fosse troppo complesso o quando lo si ritiene utile, si potrebbe riportare in ogni entità i principali attributi che la caratterizzano, oppure arricchirlo di informazioni quali ad esempio: definizione dell’entità, ente owner della definizione, dominio di business, ecc.
Nel CDM non si parla di sistemi informativi, tabelle, database, API, ecc; il CDM serve a rappresentare il business così come lo concepisce l'azienda. È scritto in linguaggio naturale, spesso rappresentato con diagrammi ER o UML, deve essere comprensibile tanto dal CTO quanto dal responsabile commerciale o dall’impiegato di contabilità. La sua funzione nell'architettura della conoscenza è fondamentale: fornisce la “materia prima” concettuale da cui si forgeranno le strutture formali dei livelli superiori.
Ontologia: dal modello concettuale alla conoscenza strutturata (Layer 2)
Il layer ontologico è il livello in cui il modello concettuale (CDM) viene tradotto in una struttura dati processabile dal sistema. Se una descrizione concettuale nel CDM dice che "un cliente può essere persona fisica o persona giuridica", l'ontologia lo formalizza come una gerarchia di classi, con assiomi logici precisi: PersonaFisica ⊑ Cliente, PersonaGiuridica ⊑ Cliente, questi due sottoinsiemi sono disgiunti.
Il linguaggio standard per la definizione di ontologie è OWL (Web Ontology Language), evoluzione del linguaggio RDFS (Resource Description Framework Schema). Questi formalismi non sono dettagli tecnici: sono necessari per abilitare un’automazione del ragionamento. Per fare un esempio: un motore di inferenza può dedurre, a partire dagli assiomi dell'ontologia, che un soggetto mai classificato esplicitamente come cliente, ma che ha effettuato un ordine, è implicitamente un cliente. È un salto enorme rispetto a un semplice schema di database, che conosce solo ciò che è stato esplicitamente inserito.
Nel contesto della Knowledge Architecture, l'ontologia formalizza e arricchisce il framework concettuale del CDM: non solo vengono definite le entità e le loro relazioni nel contesto di business specifico, ma vengono stabilite le regole e i vincoli che governano come i dati si connettono tra loro.
Il Knowledge Graph: il modello prende vita con i dati reali (Layer 3)
Un Knowledge Graph è un modello di dati semantico che organizza le informazioni in entità interconnesse (nodi) e nelle loro relazioni (archi), creando una rete strutturata comprensibile sia dagli esseri umani che dalle macchine. Mentre i database tradizionali memorizzano i dati in tabelle “rigide” (gli attributi di ogni record esistono sempre, anche se non sono valorizzati), il Knowledge Graph cattura solo le connessioni reali tra informazioni diverse.
I Knowledge Graph sono composti da quattro componenti fondamentali:
- nodi (entità), che rappresentano gli "oggetti" del dominio (clienti, prodotti, transazioni, sedi, ecc);
- archi (relazioni), che definiscono come le entità si connettono tra loro;
- etichette e proprietà, che aggiungono ricchezza semantica sia ai nodi che alle relazioni;
- ontologie, che forniscono il framework concettuale di riferimento.
La struttura fondamentale di un Knowledge Graph è la “tripla semantica”: Soggetto, Predicato, Oggetto (esempio: Prodotto_00347 - haFornitore – Azienda_Acme). Nel Knowledge Graph, ogni dato diventa una relazione esplicita, navigabile in modalità multidimensionale, interrogabile con linguaggi come SPARQL. I Knowledge Graph si implementano su Graph Database come ad esempio: Neo4j, Stardog, TigerGraph, FalkorDB. A differenza delle implementazioni su database relazionale, non presuppongono uno schema fisso e rigido: si possono sempre aggiungere nuove relazioni senza dover ricostruire tabelle.
Con l’evoluzione dell’AI generativa e l’avvento dei cosiddetti “agenti”, i Knowledge Graph sono tornati in auge in quanto sono il mezzo con cui gli agenti AI possono ragionare sui dati aziendali: ogni nodo è un'istanza di un'entità, ogni arco è una relazione semanticamente tipizzata, ogni percorso è una sequenza di passi logici che l'agente può seguire e tracciare.
Knowledge Graph vs. Graph Database: una distinzione importante
È comune confondere questi due concetti, ma è importante coglierne la differenza:
- Knowledge Graph è un modello semantico che cattura il significato di business e le relazioni, definendo cosa rappresentano i dati e come i diversi concetti si relazionano tra loro: il “cosa” e il “perché” dell'architettura informativa.
- Graph Database è invece la tecnologia infrastrutturale che memorizza e interroga i dati strutturati a grafo: il "come" e il "dove" della gestione dei dati.
Le implementazioni enterprise di maggior successo usano entrambi in combinazione: il Knowledge Graph definisce il layer semantico comprensibile agli utenti di business, mentre il Graph Database fornisce la tecnologia necessaria per permettere query veloci, analytics in tempo reale e applicazioni AI.
Il Semantic Layer: l'interfaccia condivisa (Layer 4)
Il Semantic Layer è lo strato architetturale più vicino ai data consumer, siano essi analisti, dashboard BI o agenti AI. Non è un database, non è un'ontologia: è un contratto semantico che espone metriche calcolate, dimensioni di analisi, gerarchie e un glossario di business univoco. È uno strato che estende quello che in alcuni contesti e da alcuni vendor è stato chiamato metrics layer.
Il Semantic Layer colma un limite strutturale che il Knowledge Graph da solo non riesce a superare. Infatti, un Knowledge Graph eccelle nel modellare relazioni e significato contestuale: può mappare come un cliente è connesso a un prodotto, quel prodotto a un fornitore, quel fornitore a eventi di rischio a valle. Tuttavia, non permette di definire KPI condivisi all’interno dell’organizzazione, versionabili, calcolati con le medesime logiche di aggregazione tra i vari dipartimenti. Un Knowledge Graph non ha modo di assicurare che venga applicato il medesimo calcolo da due team diversi che nella stessa riunione devono presentare i ricavi. Ormai sappiamo per esperienza che il problema raramente risiede nei dati: è un problema semantico.
È qui che il Semantic Layer porta il suo contributo decisivo: definisce metriche calcolate con formule univoche e versionabili, definisce le dimensioni di analisi utilizzabili con ogni metrica, fornisce un glossario di business “operativo” comprensibile agli analisti. Il grafo mappa ciò che è correlato, il Semantic Layer descrive quali analisi quantitative si possono fare e cosa significano.
Per gli agenti AI, questo layer è il punto di ingresso preferenziale: quando i modelli LLM interrogano i dati attraverso un layer semantico, la loro accuratezza aumenta in modo significativo. Il contesto di business descritto nel Semantic Layer e le relazioni strutturate navigabili nel grafo prevengono le allucinazioni e le interpretazioni errate dell’AI che ormai conosciamo.
Dal Conceptual Data Model al Knowledge Graph: il percorso pratico
La Knowledge Architecture non nasce da un salto improvviso: è una catena di trasformazioni incrementali che parte dal Conceptual Data Model e arriva fino al Knowledge Graph e al Semantic Layer, con input e output precisi a ogni passaggio.
Concettualizzazione (Fase 1)
Si parte dagli stakeholder: interviste, workshop, analisi della documentazione esistente. L'obiettivo è produrre un Conceptual Data Model condiviso che catturi le entità del dominio e le relazioni fondamentali. Attenzione: il CDM deve emergere dal business, non dall'IT. Il rischio maggiore è costruire un modello che rispecchi la struttura dei sistemi esistenti piuttosto che le logiche e la conoscenza del dominio di business.
Formalizzazione ontologica (Fase 2)
Il CDM viene tradotto in OWL. Le entità diventano classi, le relazioni diventano object properties, gli attributi diventano data properties. Si aggiungono assiomi quali: disgiunzioni, cardinalità, vincoli di dominio e codominio. Esistono strumenti come Protégé o funzionalità fornite dai tool di data modeling come Erwin Data Modeler che possono supportare in questa fase.
Mappatura e ingestion (Fase 3)
I dati grezzi dei sistemi sorgente, tra cui tabelle ERP, entità CRM e file strutturati, devono essere mappati sulle classi e proprietà dell'ontologia tramite regole di trasformazione (spesso espresse in R2RML o in linguaggi proprietari degli strumenti ETL). Il risultato è un primo popolamento del Knowledge Graph con le istanze realmente esistenti nei sistemi informativi dell’organizzazione.
Arricchimento e validazione (Fase 4)
Il Knowledge Graph non è mai completo alla prima iterazione. Serve arricchirlo con relazioni derivate (inferite dall'ontologia), con dati da fonti esterne, con annotazioni generate da modelli linguistici che leggono documenti non strutturati e comprendono informazioni aggiuntive. La validazione si fa con SHACL (Shapes Constraint Language): vanno definite le forme attese dei nodi e si verificano le violazioni di integrità riscontrate.
Esposizione tramite Semantic Layer (Fase 5)
Sopra il Knowledge Graph si costruisce il Semantic Layer: formule delle metriche, termini di business e eventuali alias, politiche di accesso. Questo layer può essere interrogato in linguaggio naturale dagli agenti AI tramite RAG (Retrieval-Augmented Generation) o in modalità tool-use, con l'agente che costruisce query SPARQL o Cypher per interrogare il Knowledge Graph a partire da prompt in linguaggio naturale.
Knowledge Architecture: perché ora più che mai
La domanda è legittima: perché questa architettura, esistente da decenni nel mondo del web semantico, diventa urgente proprio adesso nel contesto dei dati gestiti dalle organizzazioni?
La risposta è nell’avvento degli agenti AI e nell’opportunità di adottarli in use case aziendali per automatizzare task complessi, così da aumentare la produttività e tagliare costi operativi. Un Large Language Model, senza avere una conoscenza strutturata del contesto di business, può interrogare dati aziendali e funzionare come ottimo redattore, ma si rivela un pessimo analista: confabula, interpreta in modo inconsistente, commette errori di interpretazione “banali” per un umano. Al contrario, un agente AI dotato di accesso a un Knowledge Graph ben costruito, con un semantic layer che espone le definizioni operative e le metriche, è in grado di rispondere a domande complesse in modo affidabile, tracciabile e coerente con la realtà aziendale.
Il Knowledge Graph non è solo una fonte di dati per l'agente: è il suo modello del mondo aziendale. È ciò che permette di navigare tra entità correlate, di seguire catene causali, di rispettare le regole di business senza doverle riscrivere in ogni prompt. È ciò che fa la differenza tra un agente che impara qualcosa in maniera limitata e un agente che comprende il contesto in cui muoversi.
Governance della Knowledge Architecture: una componente imprescindibile
Con gli agenti AI che agiscono in modo autonomo sui dati aziendali, la governance del Knowledge Graph e del Semantic Layer smette di essere una best practice e diventa una necessità architetturale. Un agente autonomo agisce sulla base di ciò che comprende dal layer semantico e da cosa estrae dal Knowledge Graph; quindi, è necessaria una governance atta ad assicurare accuratezza di quanto esposto e protezioni adeguate: un agente AI che opera su definizioni obsolete e un grafo con errori non produce solo output errati, ma li propaga lungo il workflow in cui opera e potenzialmente anche ad altri processi con cui interagisce.
Una governance efficace di Semantic Layer e Knowledge Graph richiede almeno tre elementi:
- ownership delle definizioni, delle metriche, delle entità / nodi e delle relative relazioni;
- version control: tracciamento delle modifiche nel tempo;
- role-based access: quali sistemi e agenti possono accedere a quali porzioni del layer semantico e del grafo sottostante.
In un tradizionale ambiente BI di reporting e dashboarding, un errore ha generalmente un certo livello di contenimento, in quanto sono presenti analisti che hanno “sensibilità” sui dati estratti e visualizzati e possono individuare il problema, anche se con un certo effort. Con gli agenti AI, venendo a mancare questo controllo, gli errori possono propagarsi velocemente e su scala molto maggiore prima che qualcuno se ne accorga.
In parallelo a questa esigenza, la crescente pressione regolamentare (vedi EU AI Act e DORA nel settore finanziario) richiede tracciabilità ed explainability delle decisioni prese dall'AI o assistite dall’AI. Esplicitare la conoscenza aziendale in una architettura come quella descritta in questo articolo è uno dei fondamenti tecnici per assicurare questa “spiegabilità”: ogni risposta di un agente può essere ricondotta ai nodi del grafo e alle definizioni del Semantic Layer da cui è stata derivata.
La conoscenza come infrastruttura
Costruire un'architettura della conoscenza aziendale, dal CDM all'ontologia, dal Knowledge Graph al Semantic Layer, non è un progetto IT. È un investimento strategico sull'intelligibilità dei propri dati, tanto per le persone che interagiscono con essi quanto per i sistemi AI che sempre di più opereranno sui dati.
Le organizzazioni che ottengono il maggior ritorno dell’investimento e generano il maggior valore dai propri dati lo fanno eseguendo strategie e approcci avanzati che unificano e formalizzano la conoscenza a partire da asset informativi distribuiti. Il vantaggio competitivo non risiede nella quantità di dati posseduti, ma nel significato che si riesce ad attribuire loro in modo coerente, governato e accessibile.
In un'epoca in cui gli agenti AI sono destinati a diventare operatori attivi nei processi aziendali, una Knowledge Architecture non è un'opzione, bensì la piattaforma su cui costruire qualsiasi forma di intelligenza operativa affidabile.
Affrontare questo percorso con il giusto approccio fa la differenza tra iniziative isolate e un reale vantaggio competitivo. Noi siamo al fianco delle aziende che vogliono costruire un’architettura della conoscenza solida, pronta a sostenere le attuali sfide poste dall’intelligenza artificiale e tutte quelle che verranno.