

Your company relies on technology to provide services to its customers. But what if something goes wrong? Can you afford downtime?
Whether you can afford it or not, you should consider how to control network risk to maximize service availability.
Let’s outline some specific issues you might be facing right now, so you can better understand how to deal with them.
1. The baseline – overall network visibility
It is critical to have a complete view of your network. You can't control devices or infrastructures that you don't know about or have limited information about.
1.1. Inventory management
The inventory is frequently used to define the list of devices that will need to be serviced. What happens if a device breaks down and isn't being maintained?
Before you can restore service, you'll need to order a replacement, which could take days, weeks, or even months to arrive. In the best-case scenario, the service is robust, so only resiliency is impacted; nonetheless, nothing must fail while you wait for the replacement to arrive.
If the service is not resilient, it will be unavailable until the defective device is replaced - this is the worst-case scenario, and one most probably can’t afford it.
So, while we recognize the need to maintain an accurate inventory, we also realize that it can be difficult:
- What level of assurance do you have that your existing inventory is up to date?
- Has the inventory been updated to reflect the devices that were replaced last week or six months ago?
- How long does it take you to verify and regulate your inventory data?
1.2. Information and documentation
We have a similar issue with maintaining network documentation and ensuring that it is up to date. Otherwise, you risk being unable to effectively resolve any network issues that come up. Using an out-of-date schematic for change planning or troubleshooting could be quite deceptive and may result in otherwise avoidable downtime.
Obviously, you may have procedures in place to assure the accuracy of diagrams and other pertinent documents. But we all know how time-consuming this is, and let's face it – time is valuable, and you probably want to spend yours on more fascinating projects.
2. Remove errors in the network
Monitoring tools are designed to notify you when there is a problem, but what if there are certain anomalies that aren't considered issues, such as no SNMP traps or Syslog being transmitted, and you haven't noticed any symptoms because the problem is only on a backup connection or device? How do you find these inaccuracies and repair them before they have a negative impact on the service?
2.1 MTU Misconfiguration
When the MTU is not configured consistently (for example, you have a primary path that works as intended but the backup is configured incorrectly), it may cause problems. In this example, you won't discover the problem until the primary path fails.
It can be difficult to ensure that MTU is correctly configured on all devices; how long would it take you to gather, parse, and evaluate the data for all of the interfaces' MTU, so that you know how it is configured on both ends for each link?
Immediate access to links with inconsistent MTU enables you to be proactive in repairing any links that may be causing problems on your network.

2.2. No prefixes received by BGP neighbors
A second hidden issue to mention here is a BGP neighbor with no received prefixes, which can cause huge outages.
Here’s an example based on prior experience: two BGP neighbors to a service provider, but no prefixes were being received on the backup router. The BGP session was still active, therefore no problems were flagged by our monitoring tools; everything "appeared to be fine."
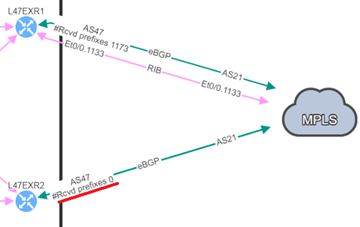
And then, the worst-case scenario came to be - we lost our principal connection, and our catastrophic downtime began. This service was inaccessible.
We were aware that the resilient path had previously worked, but we were unaware that it no longer did. How can we spot this and prevent similar problems from causing downtime?
👉 Check out this blog post for more information on this subject: IP Fabric | Network Assurance | BGP resiliency and received prefixes
These examples demonstrate how there may be network issues that you are completely in the dark about.
3. Restore services
We try to be proactive as much as possible to avoid any downtime. However, issues can arise from time to time. As a result, in order to restore service, we must be well-equipped to react quickly.
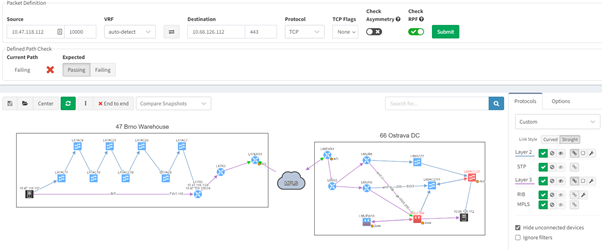
3.1. Advanced troubleshooting end-to-end path
Using IP Fabric's end-to-end path lookup, all devices involved in passing traffic from a source to a destination will be displayed in a matter of seconds. IP Fabric examines not just network data but also firewalls in the path, allowing you to see any policies that may obstruct traffic.
With such a tool at hand, it's simple to locate the source of an issue without having to connect to any devices, analyze logs on several firewalls, or waste time looking for the most recent diagram. Everything can be seen in a single, dynamic view:
3.2 Past representation of your network topology
When troubleshooting, a common issue is a lack of insight into how your network was operating previously. It would be quite handy to get a perspective of a previous topology, for example, from the previous day. Then, by comparing the two topologies, you can quickly see and understand what’s changed in your network:
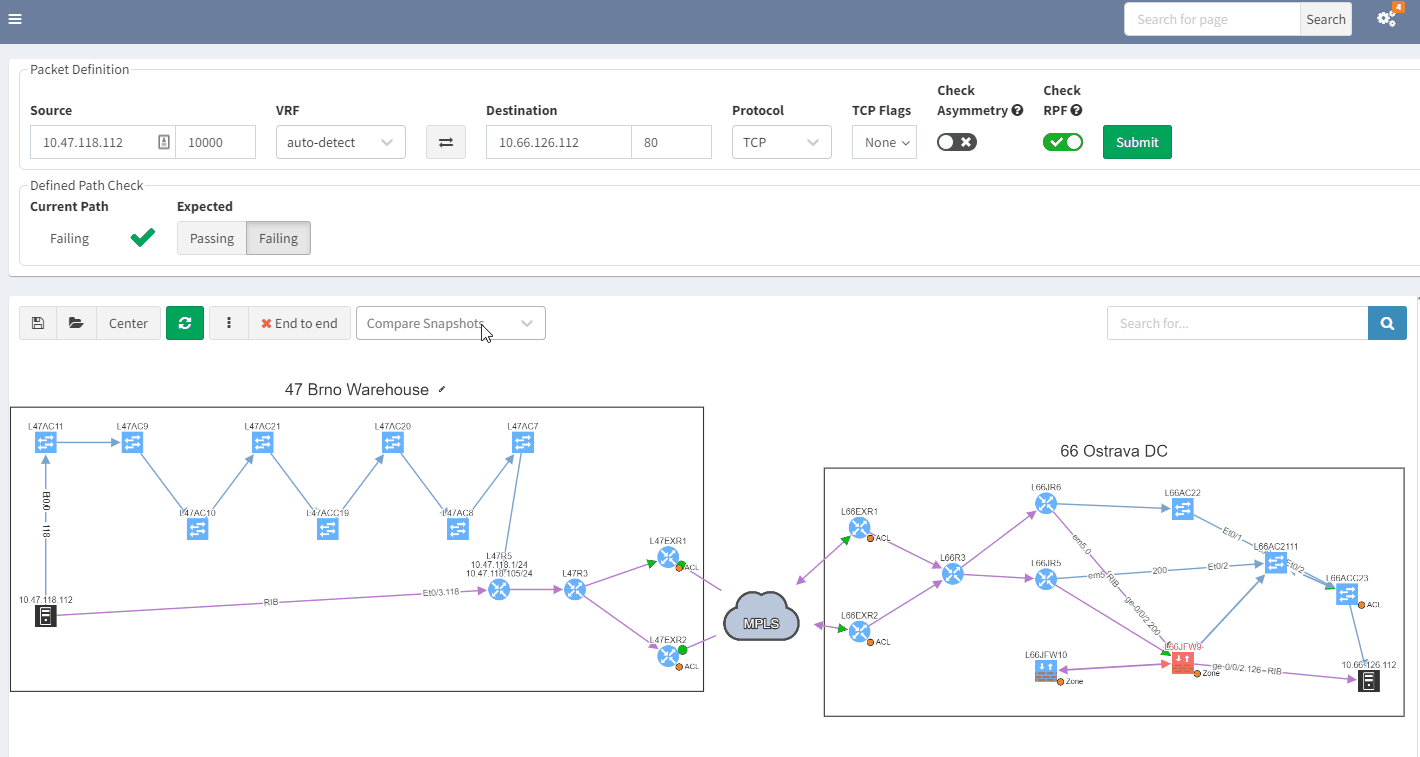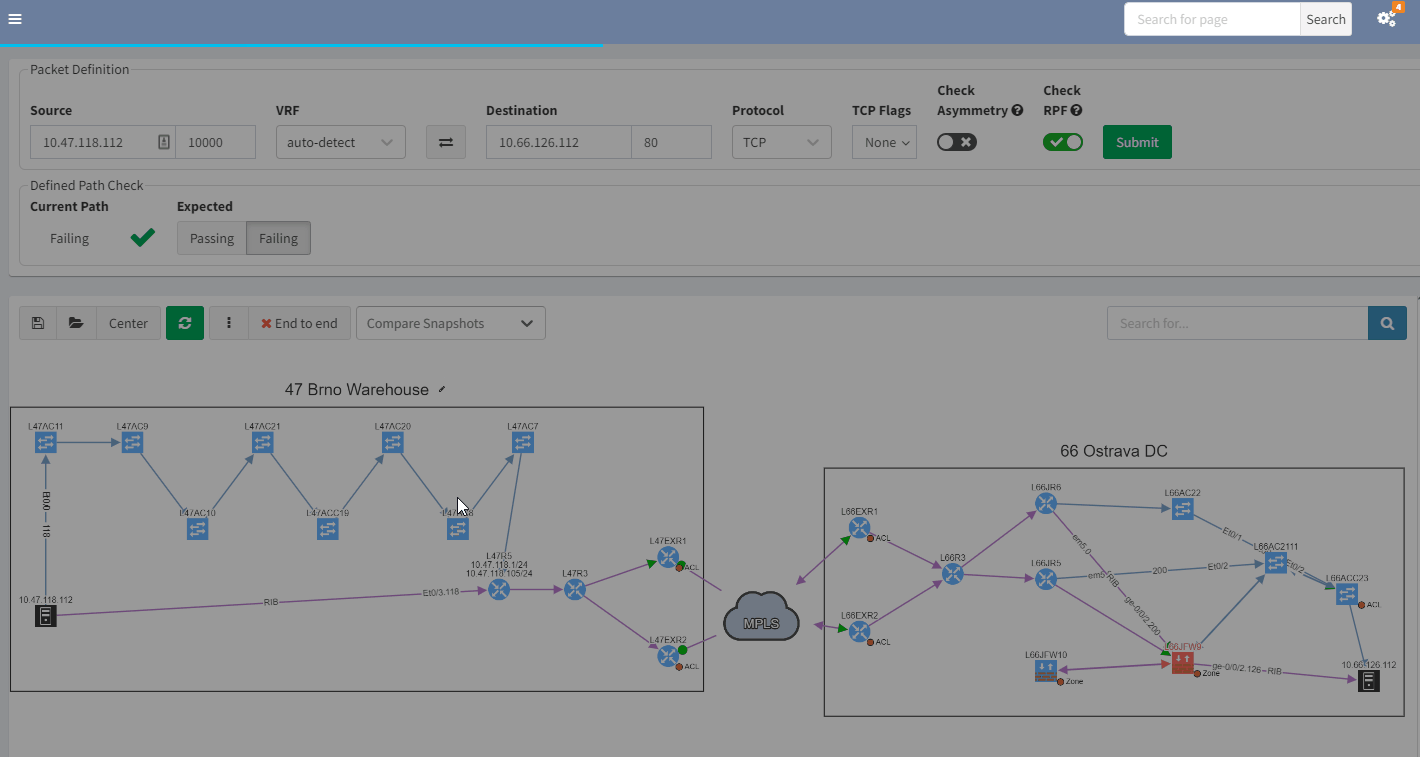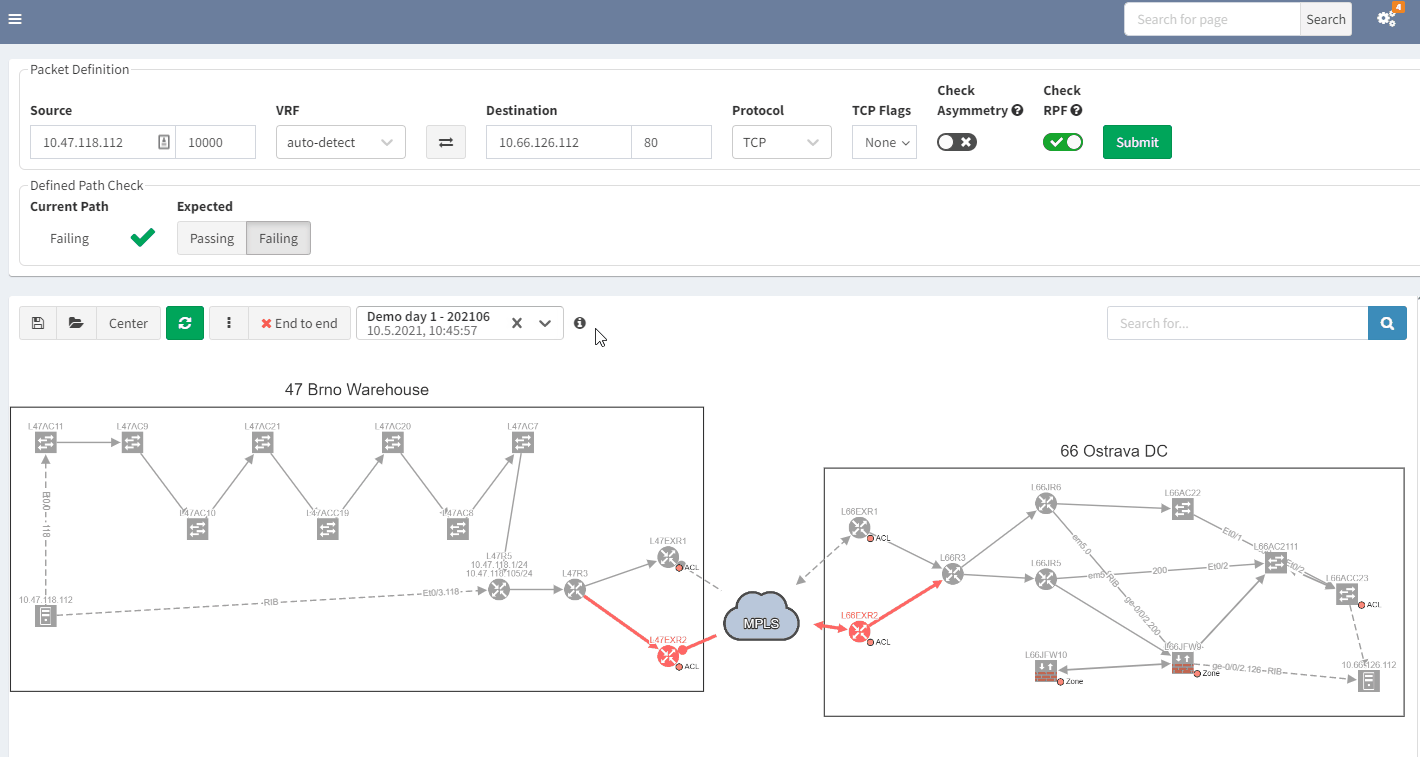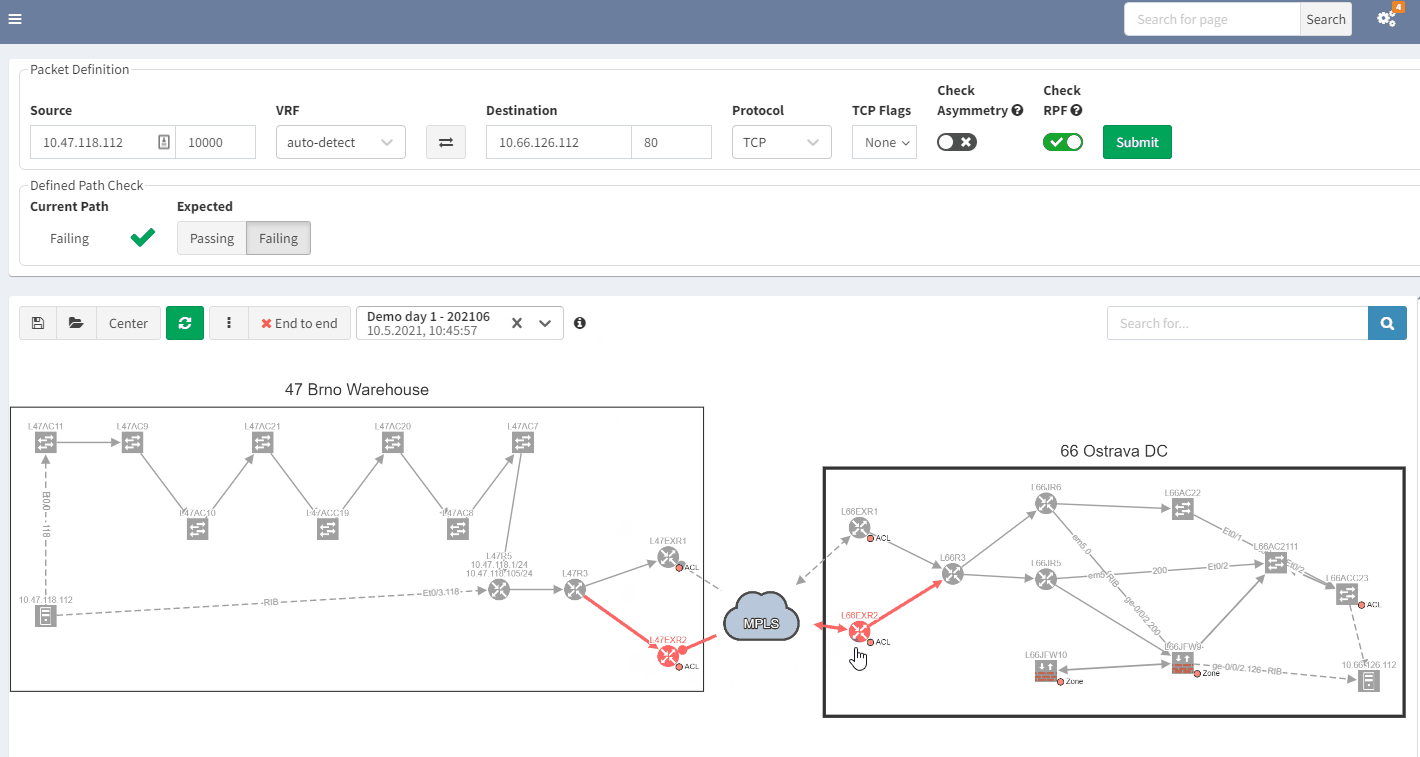
In the example above, you can see that there was only one link to the MPLS cloud in the prior snapshot; the second one in red was not present but is now operational in the most recent snapshot.
Kirey Group and IP Fabric: a winning partnership
Kirey Group leads companies in the digital transformation process, offering specific competencies in the field of system integration, strategic consulting, and technological innovation. Kirey Group is based on high-profile professionals able to face the most complex challenges of the IT market and on significant investments in research and development.
With more than 780 employees, Kirey Group is headquartered in Milan and has offices in Turin, Padua, Florence and Rome, as well as a significant presence abroad, in Spain, Portugal, Romania, Serbia, Albania, Croatia, and Kenya.
IP Fabric is an automated Network Assurance platform that - regardless of vendor - performs holistic discovery, verification, visualization, and documentation of enterprise networks, reducing the associated costs and resources required to manage them while improving security and efficiency.
IP Fabric supports the efforts of Engineering and Operations teams, enabling migration and transformation projects. IP Fabric revolutionizes the Network Governance and Assurance approach, focusing on security, automation, multi-cloud networking, and troubleshooting
👉Click here to learn more about our
Network Governance System offering!
Source of the article: https://ipfabric.io/blog/uptime-is-money-managing-network-risk-to-maximise-service-availability/