

Come l'automazione dei processi IT semplifica la gestione dell'infrastruttura: il progetto di Kirey Group per un'importante realtà della pubblica amministrazione.
A cura di Mirco Domenico Morsuillo, DevOps Engineer
Ogni azienda, sia essa attiva nell’industria o nei servizi, necessita di un’infrastruttura IT che supporti il business. E con l’aumentare dei componenti dell’infrastruttura, aumenta anche la sua complessità: quando, infatti, un’organizzazione ha centinaia di server, utenti, reti, switch e applicazioni - ciascuna con la propria versione e ambiente - l’automazione semplifica la gestione complessiva della struttura, con effetti tangibili in termini di risparmio di tempo e di risorse.
Per mettere in campo un sistema di automazione dei processi IT è necessario individuare i tool più adatti alle proprie esigenze. Sebbene Terraform sia un punto di riferimento noto per il provisioning dell'infrastruttura, Ansible, soprattutto quando affiancato da Git, può di certo fornire tutte le funzionalità per il provisioning stesso, oltre alla gestione di tutte le configurazioni lato middleware. Un tema che abbiamo approfondito anche qui. È importante notare, inoltre, che si tratta di strumenti completamente open source.
In Kirey Group un team di professionisti specializzati in Ansible da anni lavora fianco a fianco a numerose realtà enterprise nell’implementazione dell’automazione a livello infrastrutturale, misurando le potenzialità di questo tool nella sua applicazione alle più disparate architetture e tecnologie. Ansible, infatti, è versatile e riesce ad adattarsi a un vastissimo ventaglio di situazioni: basti pensare che è stato utilizzato per configurare ambienti come TXSeries, Jboss/Wildfly, F5, Docker e molti altri.
Automazione dei processi IT: il progetto di implementazione
In un recente progetto, attualmente in corso e in fase di sviluppo, il team di Kirey Group sta supportando un importante cliente della Pubblica Amministrazione nell’automatizzazione dell’installazione e della configurazione di tecnologie middleware come Wildfly, Jboss e Apache. Al momento il progetto prevede un focus sul servizio Wildfly, tramite Ansible, e sono già stati definiti i next step:
- automatizzare l’installazione e la configurazione delle tecnologie applicative del cliente (Wildfly, Jboss, Jdk, etc.) per più versioni;
- censire ed avere lo storico di tutte le configurazioni dei componenti applicativi di tutte le filiere;
- installare AWX tramite Helm/Kubernetes e quindi avere un interfaccia grafica con la quale eseguire i playbook di Ansible;
- avere un’integrazione all LDAP aziendale con cui gestire tutta la parte RBAC (accessi e permessi) di AWX.
Per prima cosa è stata fatta un’analisi delle infrastrutture e dell’organizzazione dei server del cliente per capire come gestire a lungo termine sia gli sviluppi di tutti i ruoli Ansible (che contengono i task che applicano le configurazioni), sia la gestione delle variabili dei singoli cantieri applicativi. Dopo aver approfondito la realtà del cliente, si è passati a un’analisi completa delle procedure necessarie per automatizzare un’installazione e configurazione di Wildfly, senza tralasciare eccezioni. Dopo l’analisi, è stato scomposto ogni singolo processo, da automatizzare in una serie di microprocessi fino ad arrivare ai singoli task. Nel caso di Wildfly possiamo riconoscere ad esempio i seguenti processi, non ancora scomposti:
- Creazione dell’utenza e del gruppo su cui verrà eseguito Wildfly
- Installazione della Jdk
- Installazione di Wildfly
- Configurazione di Wildfly (instalazione/configurazione di moduli, driver, logging, ecc.)
Successivamente, i processi sono stati censiti su Git per tenere traccia dei to do. Avendo visibilità degli host target, è dunque possibile procedere alla creazione contemporanea del file di inventory (file dove vengono definiti e raggruppati i sistemi target) e dei file di variabili, sia di default sia personalizzabili dall'utente finale; nel caso di Wildfly, ad esempio, tra le variabili di default si possono trovare i moduli e i driver installati di default, mentre tra le variabili personalizzate dall’utente la versione di Wildfly, l’aggiunta di moduli custom, ecc. La creazione corretta dell'inventory e dei file di variabili collegati ad esso è una parte cruciale, poiché se affrontata correttamente renderà più semplice l’utilizzo dell’automazione anche agli sviluppatori.
Dopo aver eseguito l’analisi, aver ricavato l’inventory e aver fatto una bozza dei file di variabili, inizia lo sviluppo vero e proprio. In questo caso, data la complessa infrastruttura del cliente e la necessità di riutilizzo di parte del codice per lo sviluppo di ruoli futuri (che dovranno configurare altre tecnologie applicative), si è deciso di eseguire lo sviluppo dei ruoli Ansible in modalità galaxy, ovvero ogni ruolo viene sviluppato come componente modulare su progetto Gitlab dedicato, così da poterlo richiamare/integrare in altri ruoli/playbook. Questa modalità di sviluppo richiede un effort maggiore di tempo e di accortezza rispetto a quella classica, in cui tutti i ruoli sono all’interno di un progetto e strettamente legati tra loro, poiché il ruolo deve essere “dinamico” e quindi adattarsi sulla base delle variabili che gli vengono fornite. Ad esempio, il ruolo che installa la JDK può dover installare una Open-JDK oppure un Oracle-JDK, avere una versione particolare, un path custom di installazione, o altre casistiche.
Nella prima fase l’architettura che troviamo è la seguente:
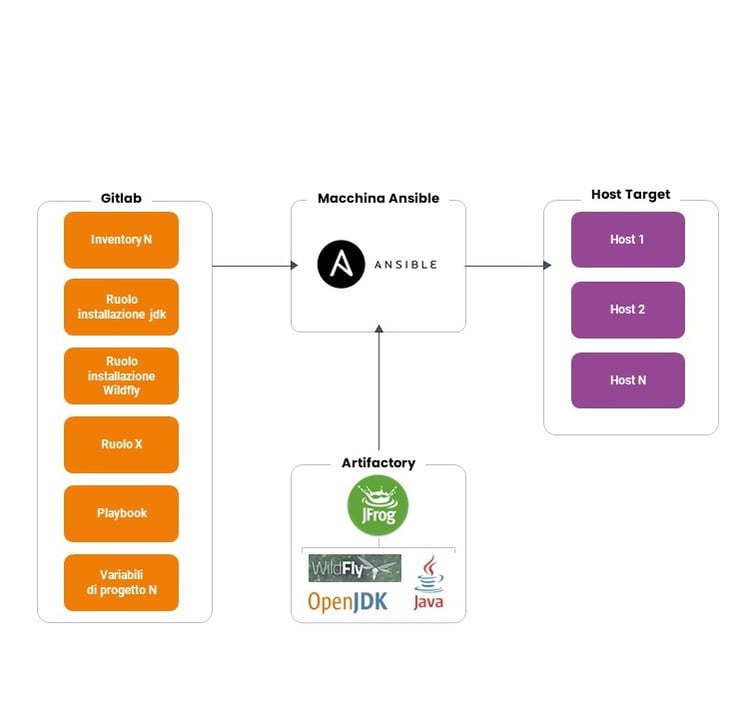
A tendere, invece, l’architettura target sarà la seguente:
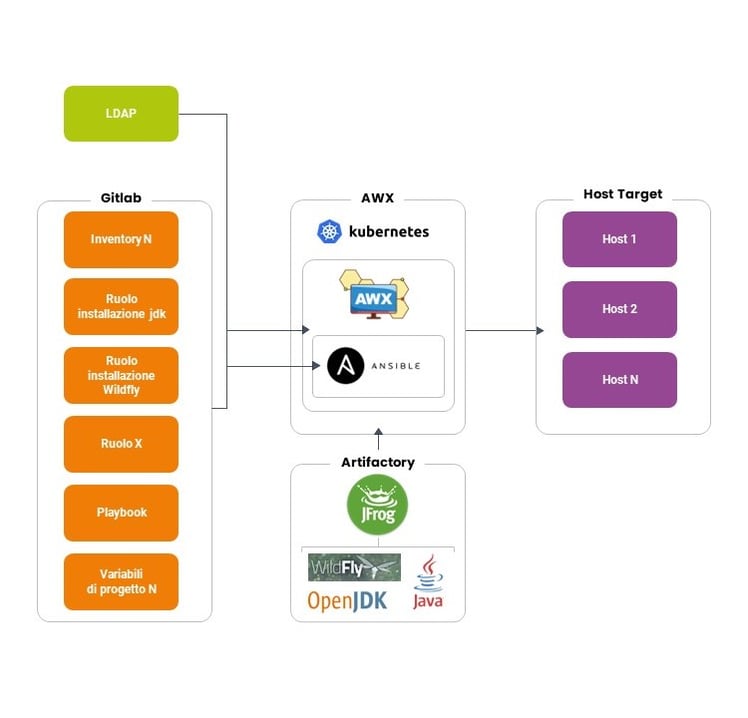
Come si può notare dai grafici, l’implementazione di AWX tramite Helm/Kubernetes rende possibile gestire gli accessi degli utenti via LDAP e gestire nel dettaglio i permessi che gli utenti hanno sull’applicare le configurazioni tramite Ansible, in questo modo, ad esempio, solo determinate persone possono effettuare modifiche in produzione. Si può anche notare come tutti i pacchetti di installazione siano presenti su Artifactory, al quale Ansible fa rifermento per i download, e il ruolo focale che ha Git nella gestione/versionamento sia del codice, sia delle variabili sia dell’organizzazione degli inventory.
Automazione dei processi IT: i vantaggi
In questo modo, il cliente ha la possibilità di configurare e riconfigurare tutte le tecnologie coperte dall’automazione; essendo salvato e versionato in Git, il codice permette al cliente di fare un immediato roll back in caso di problemi e, quindi, di riapplicare configurazioni passate. Anche a distanza di anni, sarà possibile verificare come si è evoluta la configurazione architetturale e, tramite AWX, sapere chi ha applicato quali configurazioni e quando. Si tratta di un notevole beneficio: non è scontato, infatti, avere la possibilità di riconfigurare da zero un’applicazione con un semplice passaggio, ricreando con uno sforzo minimo il cluster applicativo in caso di perdita totale dello stesso. Inoltre, questo processo dà la possibilità anche a chi non ha un’ampia conoscenza dei prodotti di applicare le configurazioni.
Questi vantaggi, insieme ad altri importanti benefici che sintetizziamo di seguito, si applicano a tutte le organizzazioni che scelgono di automatizzare i processi IT utilizzando questi tool:
- Ansible si basa sul concetto di idempotenza: ciò significa che se viene eseguito il codice una o cento volte il risultato prodotto sarà sempre lo stesso (a patto che il codice sia scritto correttamente), quindi, se per qualsiasi motivo viene danneggiata la configurazione di un sistema, può essere ripristinata in qualsiasi momento in tempi brevissimi anche da qualcuno che non conosce il prodotto in questione;
- tutte le configurazioni che vengono applicate sono salvate e versionate su Git, quindi si ha lo storico di tutte le configurazioni e le relative modifiche gestite tramite automazione;
- è possibile propagare la stessa configurazione su centinaia di sistemi, quindi se viene trovato un bug per un prodotto si può applicare la fix in tempi lampo, se paragonati a dover sistemare un server alla volta (che richiederebbe un effort di settimane, se non mesi);
- i task sviluppati per un determinato sistema operativo spesso e volentieri possono essere utilizzati anche su altre versioni dello stesso sistema operativo o addirittura su altri sistemi, spesso con zero modifiche;
- è possibile configurare nuovi cantieri in tempi molto più brevi, poiché si può riciclare in parte quanto fatto per cantieri similari;
- è possibile creare una copia speculare di un cantiere applicativo cambiando poche righe dell’inventory e del file di configurazione (che identificano i sistemi target); in questo modo si possono gestire vari ambienti come sviluppo, collaudo, produzione e altri, essendo sicuri al 100% che le configurazioni usate siano le stesse.
È evidente, quindi, il motivo per cui la maggior parte delle organizzazioni oggi si sta muovendo in questa direzione: i vantaggi superano di gran lunga l’investimento del progetto di automazione dei processi IT, che porta invece benefici a lungo termine in termini di sicurezza, funzionalità e risparmio su tempi e risorse dedicate.
