

How IT process automation simplifies infrastructure management. The project Kirey Group is carrying out for a major public organization
By Mirco Domenico Morsuillo, DevOps Engineer
Whether in industry or services, every company needs an IT infrastructure that supports the business. And as the components of the infrastructure increase, so does its complexity: when, in fact, an organization has hundreds of servers, users, networks, switches and applications - each with its own version and environment - automation simplifies the overall management of the structure, with tangible effects in terms of saving time and resources.
Developing an IT process automation system requires identifying the tools best suited to your needs. A good ally for managing the infrastructure is, for example, Terraform; for the application of all middleware-side configurations, on the other hand, Ansible is an excellent choice, especially combined with Git, where you can save parameters to be passed right to Ansible to apply them to configurations. A topic we have also explored here. It is also important to note that these are completely open-source tools.
In Kirey Group, a team of professionals specialized in Ansible has been working side by side for years with enterprise companies in the implementation of automation at the infrastructure level, measuring the potential of this tool in its application to different architectures and technologies. Ansible, in fact, is versatile and can adapt to a very wide range of situations: it has been used to configure environments such as TXSeries, Jboss/Wildfly, F5, Docker, and many others.
IT process automation: the implementation project
In a recent project, currently underway and under development, the Kirey Group team is supporting a major Public Administration client in automating the installation and configuration of middleware technologies such as Wildfly, Jboss, and Apache. Currently, the project includes a focus on the Wildfly service, via Ansible, and the next steps have already been defined:
- automate the installation and configuration of customer application technologies (Wildfly, Jboss, Jdk, etc.) for multiple versions;
- census and have the history of all configurations of application components of all supply chains;
- install AWX via Helm/Kubernetes and then have a graphical interface with which to run Ansible playbooks;
- have an integration to the enterprise LDAP with which to manage the RBAC part of AWX (access and permissions).
First, we made an analysis of the client's infrastructure and server organization to understand how to manage in the long run both the developments of all Ansible roles (which contain the tasks that apply the configurations) and the management of the variables of the individual application sites. After delving into the client's reality, we made a comprehensive analysis of the procedures needed to automate a Wildfly installation and configuration, without leaving out exceptions. After the analysis, each individual process to be automated was disassembled into a series of microprocesses, then again into individual tasks. For example, in the case of Wildfly we can recognize the following processes, which have not yet been disassembled:
- Creation of the user and group on which Wildfly will run
- Installation of the Jdk
- Installation of Wildfly
- Configuration of Wildfly (installation/configuration of modules, drivers, logging, etc.).
Next, the processes were surveyed on Git to keep track of the to-do. Having visibility of the target hosts allows to proceed with the simultaneous creation of the inventory file (file where the target systems are defined and grouped) and the variable files, both default and customizable by the end user; in the case of Wildfly, for example, among the default variables can be found the default installed modules and drivers, while among the user-customized variables the version of Wildfly, the addition of custom modules, etc. Correctly creating the inventory and variable files linked to it is a crucial part, since if addressed correctly it will make it easier for developers to use the automation as well.
After performing the analysis, deriving the inventory, and making a draft of the variable files, the actual development begins. In this case, given the client's complex infrastructure and the need to reuse some of the code for the development of future roles (which will need to configure other application technologies), it was decided to perform Ansible role development in the galaxy mode. This means that each role is developed as a modular component on a dedicated Gitlab project, so that it can be recalled/integrated into other roles/playbooks. This mode of development requires a greater effort of time and shrewdness than the classic mode, in which all roles are within a project and tightly bound together since the role must be "dynamic" and adapted by the variables provided to it. For example, the role that installs the JDK may have to install an Open JDK or Oracle JDK, have a particular version, a custom installation path, or other case scenarios.
In the first phase, the architecture we find is as follows:
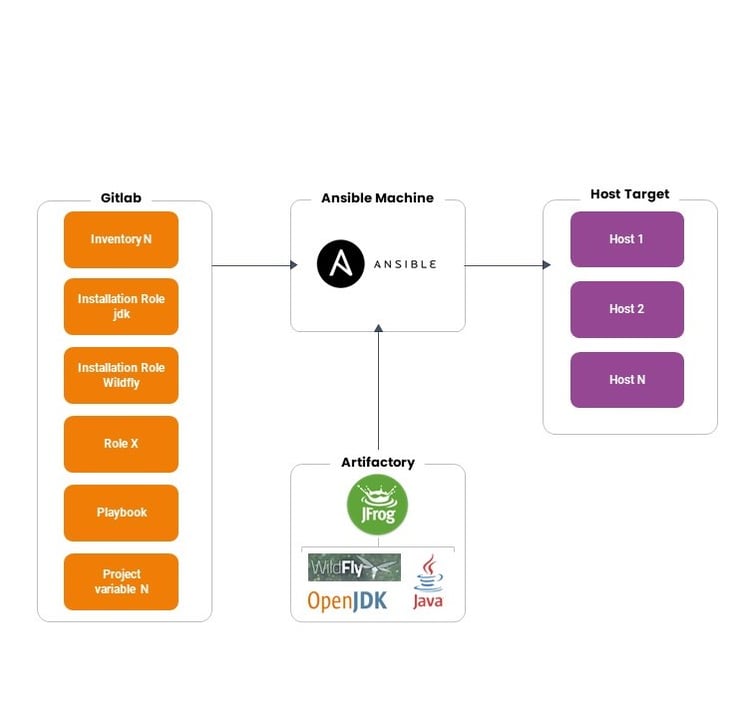
Instead, we’re working on a target architecture as follows:
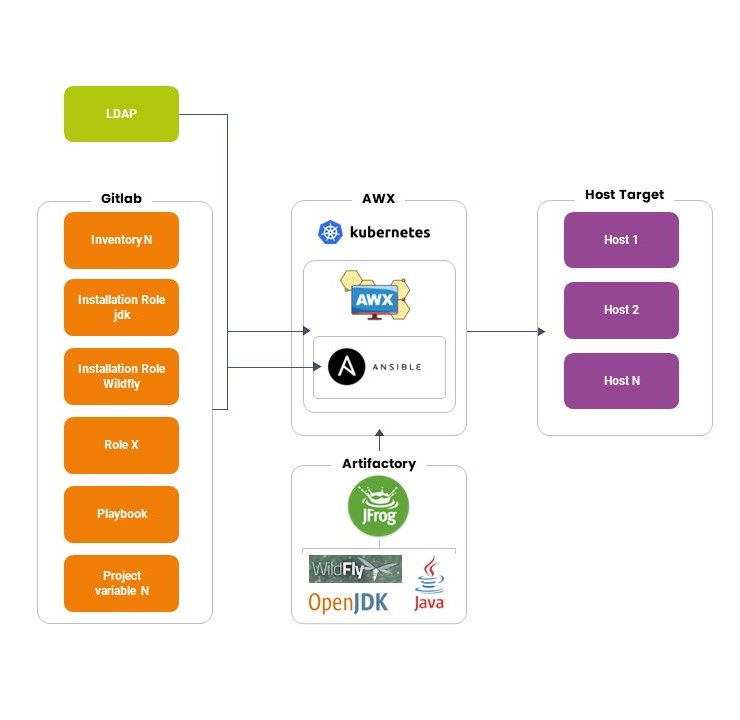
As can be seen from the schemes, the implementation of AWX via Helm/Kubernetes makes it possible to manage user access via LDAP and to manage in detail the permissions that users have on applying configurations via Ansible, so that, for example, only certain people can make changes in production. You can also see how all installation packages are on Artifactory, which Ansible refers to for downloads, and the focal role Git has in managing/versioning both code, variables, and inventory organization.
IT process automation: the benefits
In this way, the client has the ability to configure and reconfigure all technologies covered by automation; being saved and versioned in Git, the code allows the client to immediately roll back in case of problems and, thus, reapply past configurations. Even years later, it will be possible to check how the architectural configuration has evolved and, through AWX, to know who applied which configurations and when. This is a significant benefit: it is not taken for granted to have the ability to reconfigure an application from scratch in one easy step, recreating the application cluster with minimal effort in the event of its total loss. In addition, this process gives even those without extensive product knowledge the ability to apply configurations.
These advantages, along with other important benefits that we summarize below, apply to all organizations that choose to automate IT processes using these tools:
- Ansible is based on idempotency: this means that if code is executed once or a hundred times the result produced will always be the same (provided the code is written correctly), so if for any reason the configuration of a system is damaged, it can be restored at any time in a very short time even by someone who does not know the product very well;
- all configurations that are applied are saved and versioned on Git, so you have the history of all configurations and their changes managed through automation;
- you can propagate the same configuration across hundreds of systems, so if a bug is found for a product you can apply the fix in lightning time when compared to having to fix one server at a time (which would take an effort of weeks or even months);
- tasks developed for a given operating system can often and happily be used on other versions of the same operating system or even other systems, often with zero changes;
- it is possible to set up new worksites in a much shorter time since you can recycle in part what has been done for similar worksites;
- you can create a mirror copy of an application worksite by changing a few lines of the inventory and configuration file (which identify the target systems); in this way you can manage various environments such as development, testing, production, and others, being 100% sure that the configurations used are the same.
In conclusion, it is obvious why most organizations today are moving in this direction: the benefits far outweigh the investment of the IT process automation project, which brings long-term benefits in terms of security, functionality, and savings on time and resources.
