

Companies have been generating and accumulating data for decades across systems such as ERP, CRM, Excel spreadsheets, Data Warehouses, application logs, emails, documents, and files in the most diverse formats. It is an enormous, distributed, more or less accessible, and sometimes redundant asset. And yet, if we asked an analyst, a manager, or a new employee what operating margin means for the company and how it is calculated, we would likely receive uncertain or even conflicting answers. Why does this happen, and how can it be solved?
Key Points
- Without a shared Knowledge Architecture, AI agents cannot correctly interpret the meaning of enterprise data: an explicit and governed semantic layer is needed to transform fragmented information into reliable knowledge.
- Knowledge Architecture is built through an evolutionary journey composed of different progressive layers: starting from the Conceptual Data Model and evolving toward Knowledge Graphs and Semantic Layers. Each phase produces structured information assets that feed the next one.
- Governance of the Knowledge Architecture is an architectural necessity, because AI agents base decisions and actions on what they understand from the semantic layer: outdated definitions, incorrect relationships, or insufficient controls risk propagating errors across workflows and interconnected processes.
A widespread problem: the lack of a common language and a unified understanding of enterprise data
The problem just described is well known, but with the rise of AI agents — autonomous systems capable of reading, querying, reasoning over enterprise data, and sometimes making decisions and taking actions — the issue becomes critical. The reason is that an AI agent cannot easily “infer from context” what the company means by active customer, finished product, or net revenue. It needs an explicit, formal, and navigable semantic contract. It needs a Knowledge Architecture.
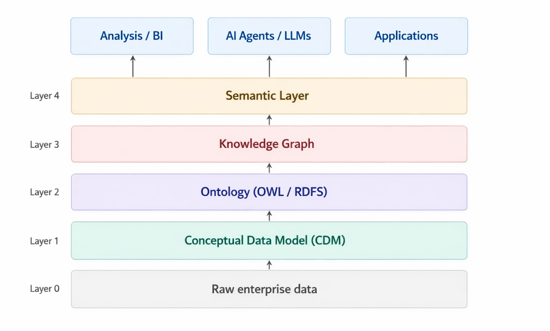
Knowledge Architecture: four concepts, one single chain
Before exploring how to build this Knowledge Architecture, it is necessary to clearly understand four different expressions that are often misused or overlapped: Conceptual Data Model, Ontology, Knowledge Graph, and Semantic Layer. They are not synonyms, but different layers of a single architecture, each with a very specific role.
Conceptual Data Model, the representation of the business world (Layer 1)
The Conceptual Data Model (CDM) is the starting point of Knowledge Architecture. It is a conceptual representation of the business context, independent of any technology used for creating, acquiring, or managing data. Its purpose is to represent the entities most relevant to the business (for example: customer, product, supplier, sales order, invoice, accounting entry, employee, etc.) and how they relate to one another (for example: a customer places orders, an order contains products). In some contexts, if the CDM is not excessively complex or when considered useful, the main attributes characterizing each entity may also be included, or it may be enriched with information such as: entity definition, owner of the definition, business domain, etc.
The CDM does not refer to information systems, tables, databases, APIs, and so on; it serves to represent the business as conceived by the organization itself. It is written in natural language, often represented through ER or UML diagrams, and must be understandable both to the CTO and to the sales manager or accounting employee. Its role in the Knowledge Architecture is fundamental: it provides the conceptual “raw material” from which the formal structures of the upper layers are built.
Ontology: from conceptual model to structured knowledge (Layer 2)
The ontological layer is the level where the conceptual model (CDM) is translated into a data structure processable by the system. If a conceptual description in the CDM states that “a customer may be either an individual or a legal entity,” the ontology formalizes this as a hierarchy of classes, with precise logical axioms: Individual ⊑ Customer, LegalEntity ⊑ Customer, and these two subsets are disjoint.
The standard language for defining ontologies is OWL (Web Ontology Language), an evolution of RDFS (Resource Description Framework Schema). These formalisms are not technical details: they are necessary to enable automated reasoning. For example, an inference engine can deduce from the ontology’s axioms that a subject never explicitly classified as a customer, but who has placed an order, is implicitly a customer. This is a huge leap compared to a simple database schema, which only knows what has been explicitly entered.
Within the Knowledge Architecture context, the ontology formalizes and enriches the conceptual framework of the CDM: not only are entities and their relationships within the specific business context defined, but also the rules and constraints governing how data connects.
The Knowledge Graph: the model comes to life through real data (Layer 3)
A Knowledge Graph is a semantic data model that organizes information into interconnected entities (nodes) and their relationships (edges), creating a structured network understandable by both humans and machines. While traditional databases store data in “rigid” tables (attributes for each record always exist, even when empty), the Knowledge Graph captures only the actual connections between different pieces of information.
Knowledge Graphs consist of four fundamental components:
- nodes (entities), representing the “objects” of the domain (customers, products, transactions, locations, etc.);
- edges (relationships), defining how entities connect to one another;
- labels and properties, adding semantic richness to both nodes and relationships;
- ontologies, providing the conceptual framework of reference.
The fundamental structure of a Knowledge Graph is the “semantic triple”: Subject, Predicate, Object (example: Product_00347 – hasSupplier – Company_Acme). In the Knowledge Graph, every piece of data becomes an explicit relationship, navigable multidimensionally and queryable with languages such as SPARQL. Knowledge Graphs are implemented on Graph Databases such as Neo4j, Stardog, TigerGraph, and FalkorDB. Unlike relational database implementations, they do not require a fixed and rigid schema: new relationships can always be added without rebuilding tables.
With the evolution of generative AI and the emergence of so-called “agents,” Knowledge Graphs have returned to prominence because they represent the native format in which AI agents can reason over enterprise data: every node is an instance of an entity, every edge is a semantically typed relationship, and every path is a sequence of logical steps that the agent can follow and trace.
Knowledge Graph vs. Graph Database: an important distinction
These two concepts are often confused, but it is important to understand the difference:
- A Knowledge Graph is a semantic model that captures business meaning and relationships, defining what the data represents and how different concepts relate to one another: the “what” and the “why” of the information architecture.
- A Graph Database, instead, is the infrastructural technology that stores and queries graph-structured data: the “how” and the “where” of data management.
The most successful enterprise implementations use both together: the Knowledge Graph defines the semantic layer understandable to business users, while the Graph Database provides the technology required for fast queries, real-time analytics, and AI applications.
The Semantic Layer: the shared interface (Layer 4)
The Semantic Layer is the architectural layer closest to data consumers, whether they are analysts, BI dashboards, or AI agents. It is not a database, nor an ontology: it is a semantic contract exposing calculated metrics, analysis dimensions, hierarchies, and a shared business glossary. It is a layer extending what in some contexts and by some vendors has been called the metrics layer.
The Semantic Layer fills a structural gap that the Knowledge Graph alone cannot solve. In fact, a Knowledge Graph excels at modeling relationships and contextual meaning: it can map how a customer is connected to a product, that product to a supplier, and that supplier to downstream risk events. However, it cannot define shared KPIs across the organization, versioned and calculated using the same aggregation logic across departments. A Knowledge Graph has no way to ensure that the same revenue calculation is applied by two different teams presenting results in the same meeting. Experience has shown that the problem rarely lies in the data itself: it is a semantic problem.
This is where the Semantic Layer provides its decisive contribution: it defines metrics calculated with unique and versionable formulas, defines the dimensions of analysis usable with each metric, and provides an “operational” business glossary understandable to analysts. The graph maps what is connected, while the Semantic Layer describes what quantitative analyses can be performed and what they mean.
For AI agents, this layer is the preferred entry point: when LLM models query data through a semantic layer, their accuracy significantly improves. The business context described in the Semantic Layer and the structured relationships navigable within the graph prevent the hallucinations and misinterpretations of AI that are now well known.
From Conceptual Data Model to Knowledge Graph: the practical journey
The Knowledge Architecture does not emerge through a sudden leap: it is a chain of incremental transformations starting from the Conceptual Data Model and reaching the Knowledge Graph and Semantic Layer, with precise inputs and outputs at every stage.
Conceptualization (Phase 1)
The process starts with stakeholders: interviews, workshops, and analysis of existing documentation. The objective is to produce a shared Conceptual Data Model capturing domain entities and fundamental relationships. Attention: the CDM must emerge from the business, not from IT. The greatest risk is building a model reflecting existing system structures rather than the logic and knowledge of the business domain.
Ontological formalization (Phase 2)
The CDM is translated into OWL. Entities become classes, relationships become object properties, and attributes become data properties. Axioms such as disjointness, cardinalities, and domain/range constraints are added. Tools such as Protégé or functionalities provided by data modeling tools like Erwin Data Modeler can support this phase.
Mapping and ingestion (Phase 3)
Raw data from source systems — including ERP tables, CRM entities, and structured files — must be mapped to ontology classes and properties through transformation rules (often expressed in R2RML or proprietary ETL tool languages). The result is the first population of the Knowledge Graph with the actual instances existing in the organization’s information systems.
Enrichment and validation (Phase 4)
A Knowledge Graph is never complete at the first iteration. It must be enriched with derived relationships (inferred from the ontology), data from external sources, and annotations generated by language models capable of reading unstructured documents and understanding additional information. Validation is performed through SHACL (Shapes Constraint Language): expected node shapes are defined, and integrity violations are verified.
Exposure through the Semantic Layer (Phase 5)
Above the Knowledge Graph, the Semantic Layer is built: metric formulas, business terms and aliases, and access policies. This layer can be queried in natural language by AI agents through RAG (Retrieval-Augmented Generation) or in tool-use mode, with the agent building SPARQL or Cypher queries to interrogate the Knowledge Graph starting from natural language prompts.
Knowledge Architecture: why now more than ever
The question is legitimate: why does this architecture, existing for decades in the semantic web world, become urgent precisely now in the context of organizational data?
The answer lies in the rise of AI agents and the opportunity to adopt them in enterprise use cases to automate complex tasks, increase productivity, and reduce operational costs. A Large Language Model, without structured knowledge of the business context, can query enterprise data and function as an excellent writer, but proves to be a poor analyst: it hallucinates, interprets inconsistently, and makes interpretation errors that are “trivial” for humans. By contrast, an AI agent with access to a well-built Knowledge Graph and a Semantic Layer exposing operational definitions and metrics can answer complex questions in a reliable, traceable, and business-consistent way.
The Knowledge Graph is not merely a data source for the agent: it is its model of the business world. It allows navigation across related entities, following causal chains, and respecting business rules without rewriting them into every prompt. It is the difference between an agent that learns something superficially and an agent that truly understands the context in which it operates.
Governance of the Knowledge Architecture: an essential component
With AI agents autonomously acting on enterprise data, governance of the Knowledge Graph and Semantic Layer ceases to be a best practice and becomes an architectural necessity. An autonomous agent acts based on what it understands from the semantic layer and extracts from the Knowledge Graph; therefore, governance is required to ensure accuracy and proper protections. An AI agent operating on outdated definitions and an erroneous graph does not merely produce incorrect outputs — it propagates them across workflows and potentially to other interconnected processes.
Effective governance of Semantic Layers and Knowledge Graphs requires at least three elements:
-
ownership of definitions, metrics, entities/nodes, and their relationships;
-
version control: tracking changes over time;
-
role-based access: determining which systems and agents can access which portions of the semantic layer and the underlying graph.
In a traditional BI reporting and dashboarding environment, an error is usually somewhat contained because analysts have “sensitivity” toward extracted and visualized data and can identify the issue, albeit with effort. With AI agents, lacking this control, errors can propagate quickly and on a much larger scale before anyone notices.
At the same time, increasing regulatory pressure (such as the EU AI Act and DORA in the financial sector) requires traceability and explainability of AI-driven or AI-assisted decisions. Explicitly structuring enterprise knowledge within an architecture like the one described in this article is one of the technical foundations necessary to ensure this explainability: every agent response can be traced back to graph nodes and Semantic Layer definitions from which it was derived.
Knowledge as infrastructure
Building an enterprise Knowledge Architecture — from the CDM to the ontology, from the Knowledge Graph to the Semantic Layer — is not an IT project. It is a strategic investment in the intelligibility of data, both for people interacting with it and for AI systems that will increasingly operate on that data.
Organizations generating the greatest return on investment and value from their data do so by executing advanced strategies and approaches that unify and formalize knowledge starting from distributed information assets. Competitive advantage does not lie in the quantity of data owned, but in the meaning that can be consistently, governably, and accessibly attributed to it.
In an era where AI agents are destined to become active operators within business processes, a Knowledge Architecture is not an option, but the platform on which any form of reliable operational intelligence must be built.
Approaching this journey with the right methodology makes the difference between isolated initiatives and a real competitive advantage. We stand alongside companies that want to build a solid Knowledge Architecture, ready to support both the current challenges posed by artificial intelligence and all those yet to come.